J’ai fait tourner Prometheus + Grafana pendant deux ans sur ma stack self-hosted. Ça marchait. Mais le maintenir était un travail à mi-temps que je n’avais pas signé.
Voici l’histoire de comment j’ai remplacé une stack de monitoring de 5 conteneurs par un seul — et ce que j’ai gagné et perdu dans le processus.
Ma Stack Prometheus
Mon setup de monitoring ressemblait à ça :
services:
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
grafana:
image: grafana/grafana:latest
volumes:
- grafana-data:/var/lib/grafana
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
node-exporter:
image: prom/node-exporter:latest
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
alertmanager:
image: prom/alertmanager:latest
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
Cinq conteneurs. Trois fichiers de config. ~600 Mo de RAM au repos.
Les Points de Douleur
1. Maintenance des fichiers de config
Chaque fois que j’ajoutais un nouveau service, je devais :
- Ajouter le service dans
docker-compose.yml - Ajouter un scrape target dans
prometheus.yml - Créer ou mettre à jour un dashboard Grafana
- Parfois ajouter des règles d’alerte dans un fichier séparé
Quatre fichiers à mettre à jour pour un nouveau service.
2. L’appétit de cAdvisor
cAdvisor à lui seul consommait 150-200 Mo de RAM. Sur mon VPS de 4 Go, c’était une part significative — juste pour exposer des métriques conteneurs que Prometheus pouvait scraper.
3. La prolifération des dashboards
Après deux ans, j’avais 12 dashboards Grafana. La moitié était cassée parce que j’avais renommé des conteneurs ou changé des labels. L’autre moitié montrait des données que je ne regardais jamais.
4. La fatigue PromQL
Je suis développeur, pas SRE. Écrire des requêtes PromQL comme rate(container_cpu_usage_seconds_total{name="api"}[5m]) pour répondre à “est-ce que mon API consomme trop de CPU ?” revenait à utiliser une tronçonneuse pour couper du pain.
5. La stack de monitoring elle-même
Deux fois en deux ans, ma stack de monitoring est tombée pendant que mes services tournaient normalement. Une fois parce que Prometheus manquait de disque. Une fois parce qu’une mise à jour de plugin Grafana a cassé une datasource.
Qui monitore le monitoring ?
La Migration
Étape 1 : Déployer Maintenant à côté de Prometheus
services:
maintenant:
image: ghcr.io/kolapsis/maintenant:latest
ports:
- "8081:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /proc:/host/proc:ro
- maintenant-data:/data
environment:
MAINTENANT_ADDR: "0.0.0.0:8080"
MAINTENANT_DB: "/data/maintenant.db"
restart: unless-stopped
J’ai fait tourner les deux stacks en parallèle pendant deux semaines. Maintenant sur le port 8081, Prometheus + Grafana sur le port 3000.
Étape 2 : Ajouter des labels Docker pour les endpoints
services:
api:
image: myapp:latest
labels:
maintenant.endpoint.http: "http://api:3000/health"
maintenant.endpoint.interval: "15s"
postgres:
labels:
maintenant.endpoint.tcp: "postgres:5432"
Étape 3 : Comparer
Après deux semaines, j’ai comparé ce que chaque stack me montrait :
| Question | Prometheus + Grafana | Maintenant |
|---|---|---|
| Mes conteneurs tournent-ils ? | ✓ (via cAdvisor + dashboard custom) | ✓ (auto-découvert) |
| Mon API répond-elle ? | ✓ (via Blackbox Exporter, encore un conteneur) | ✓ (labels Docker) |
| Mes certificats SSL sont-ils valides ? | ✗ (je vérifiais manuellement) | ✓ (auto-détecté) |
| Mon backup cron tourne-t-il ? | ✗ (je n’avais pas de monitoring pour ça) | ✓ (système de heartbeat) |
| Quels conteneurs ont des mises à jour ? | ✗ | ✓ (scan digest OCI) |
| CPU/RAM par conteneur ? | ✓ | ✓ |
| Espace disque ? | ✓ | ✓ |
Maintenant couvrait tout ce que je regardais réellement dans Grafana — plus le suivi SSL, le monitoring cron et la détection de mises à jour que je n’avais pas avant.
Étape 4 : Supprimer la stack Prometheus
docker compose stop prometheus grafana cadvisor node-exporter alertmanager
docker compose rm -f prometheus grafana cadvisor node-exporter alertmanager
Puis j’ai supprimé prometheus.yml, alertmanager.yml, et les configs de datasource Grafana.
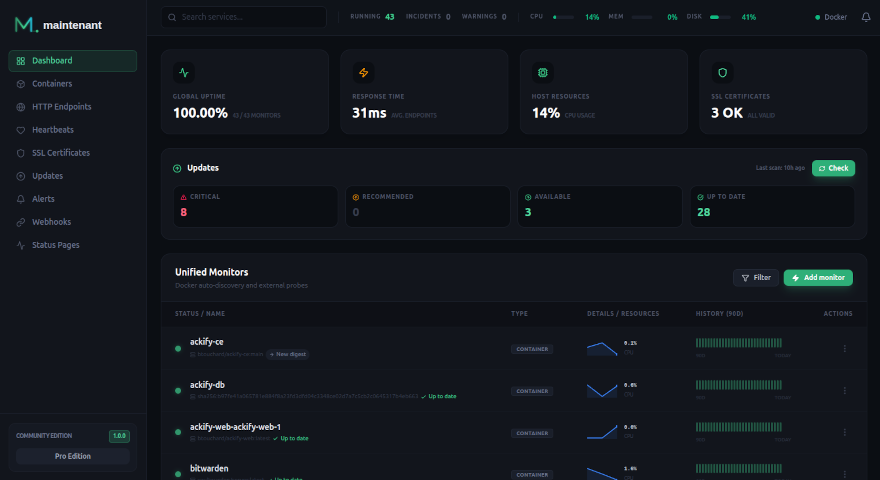
Ce Que J’ai Gagné
- 500+ Mo de RAM récupérés sur mon VPS de 4 Go
- 3 fichiers de config supprimés (prometheus.yml, alertmanager.yml, configs Grafana)
- 4 conteneurs retirés de ma stack
- Monitoring SSL que je n’avais pas avant
- Monitoring des cron jobs que je n’avais pas avant
- Détection des mises à jour que je n’avais pas avant
- Zéro maintenance — plus de dashboards cassés ni de scrape targets obsolètes
Ce Que J’ai Perdu
- PromQL — je ne peux plus écrire de requêtes ad-hoc pour explorer les métriques
- Dashboards personnalisés — plus de constructions de mes propres visualisations
- Granularité à la seconde — Maintenant collecte toutes les 30-60 secondes
- Données historiques — j’ai exporté mes données Prometheus mais ne peux pas les requêter dans Maintenant
Pour mon cas d’usage — une stack self-hosted d’environ 20 conteneurs — aucune de ces pertes ne compte. Je n’ai jamais utilisé PromQL autrement qu’en copiant-collant depuis Stack Overflow. Mes dashboards custom étaient principalement cassés. Les données à la seconde étaient du bruit pour mes besoins.
Est-ce que je reviendrais en arrière ?
Non. La charge opérationnelle de maintenir 5 conteneurs et 3 fichiers de config pour le monitoring ne valait pas le coup pour une stack de ma taille. Maintenant me donne tout ce dont j’ai réellement besoin dans un conteneur avec zéro config.
Si ma stack grossit à 200+ conteneurs sur plusieurs clusters, je reconsidérerai peut-être Prometheus. Mais pour l’instant, un conteneur suffit.