Vous avez déployé votre stack avec Docker Compose. Vos conteneurs tournent. Tout semble fonctionner. Mais que se passe-t-il quand quelque chose casse à 3h du matin ?
Ce guide couvre les 6 dimensions essentielles du monitoring pour Docker Compose, et comment les mettre en place efficacement.
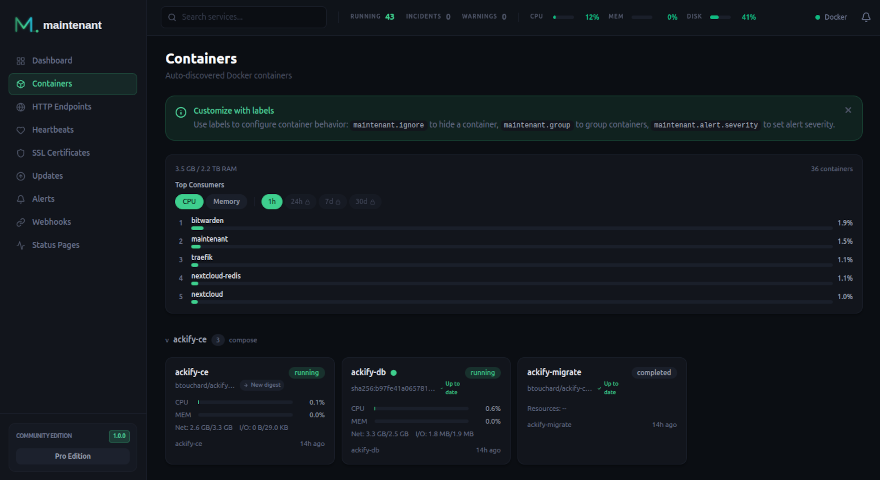
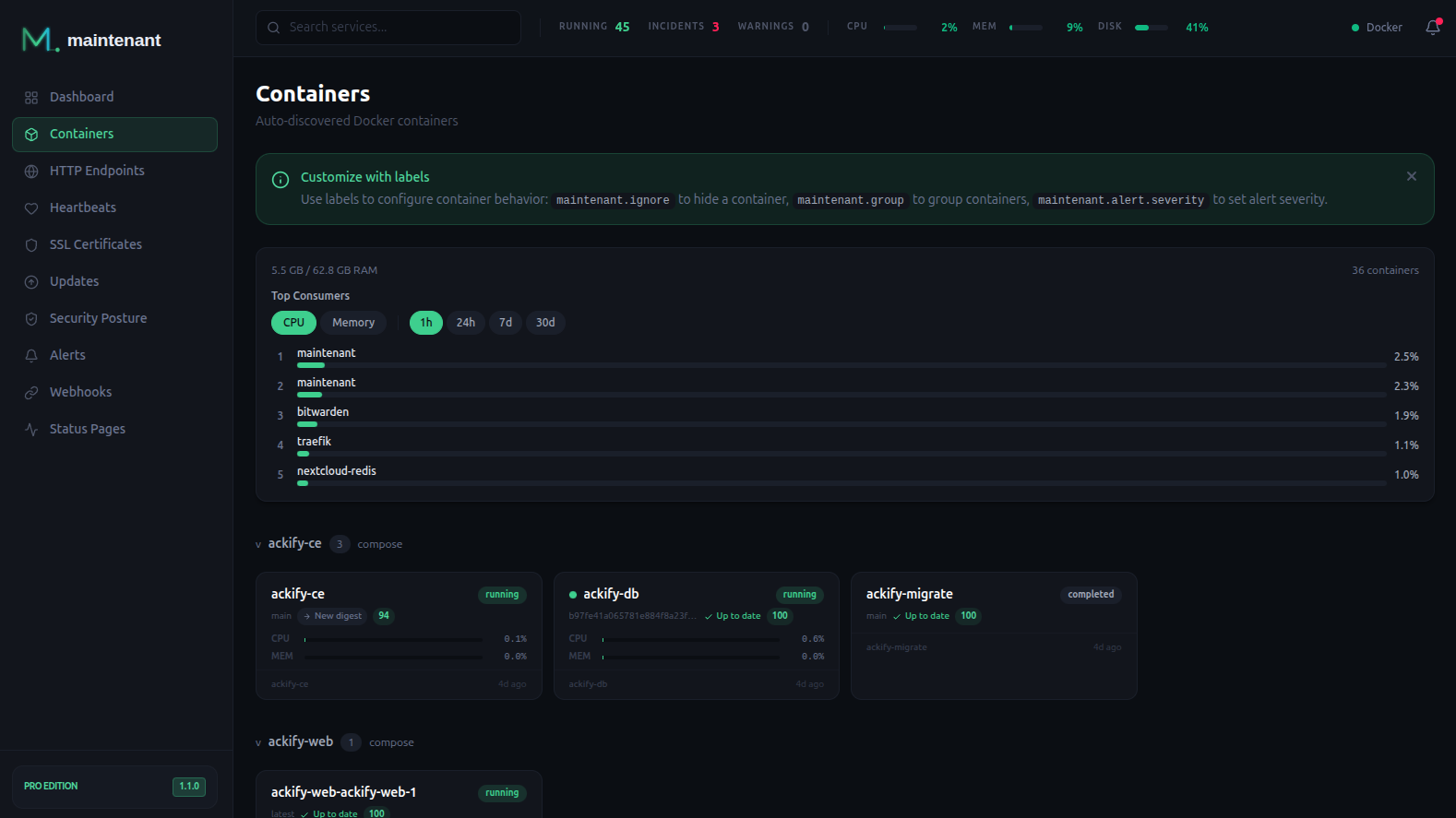
1. Monitoring des conteneurs
Le niveau le plus basique : est-ce que vos conteneurs tournent ?
Ce qu’il faut surveiller
- État du conteneur — running, stopped, restarting, exited
- Boucles de redémarrage — un conteneur qui restart en boucle est souvent pire qu’un conteneur arrêté
- Health checks Docker — le HEALTHCHECK natif de Docker est sous-utilisé mais extrêmement utile
- Codes de sortie — un exit code non-zéro indique un crash, pas un arrêt propre
Health checks dans votre docker-compose.yml
services:
api:
image: myapp:latest
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
Maintenant lit automatiquement les résultats des health checks Docker et vous alerte quand un conteneur passe en unhealthy.
2. Monitoring des endpoints
Vérifier que vos services répondent correctement aux requêtes.
HTTP checks
Au-delà du simple “est-ce que ça répond”, un bon check HTTP vérifie :
- Le code de statut (200, 201, etc.)
- Le temps de réponse (latence)
- Le contenu de la réponse (assertion sur le body)
- La validité du certificat SSL
Avec Maintenant, vous configurez ça directement en labels Docker :
labels:
maintenant.endpoint.http: "https://api.example.com/health"
maintenant.endpoint.interval: "30s"
maintenant.endpoint.http.expected-status: "200"
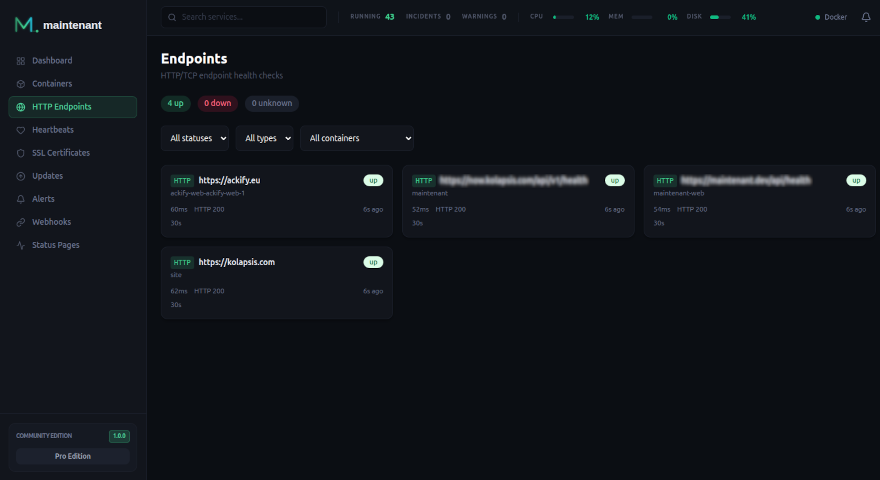
TCP checks
Pour les services qui ne parlent pas HTTP — bases de données, Redis, MQTT — un check TCP vérifie que le port est ouvert et accepte les connexions :
labels:
maintenant.endpoint.tcp: "postgres:5432"
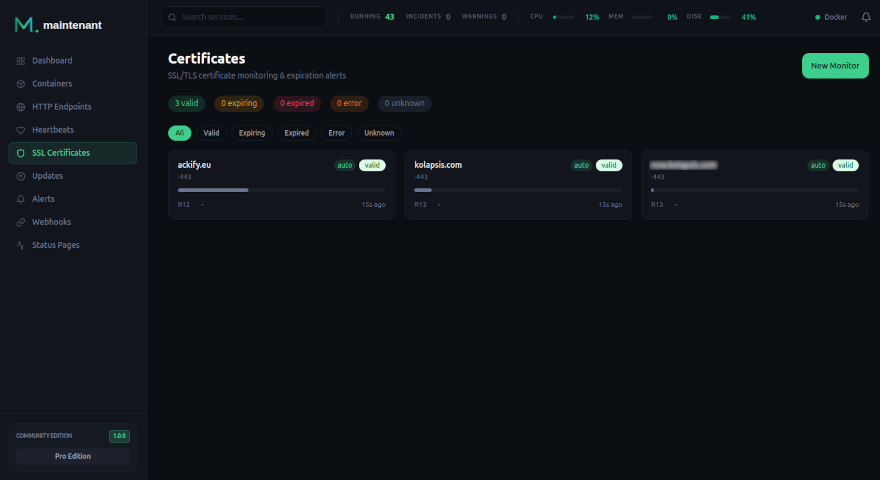
3. Monitoring des certificats SSL
Les certificats qui expirent sont l’une des causes les plus fréquentes de downtime évitable. Avec Let’s Encrypt et le renouvellement automatique, on a tendance à oublier que ça peut échouer silencieusement.
Maintenant détecte automatiquement les certificats SSL de tous vos endpoints HTTPS et vous alerte à 30, 14, 7, 3 et 1 jour avant expiration.
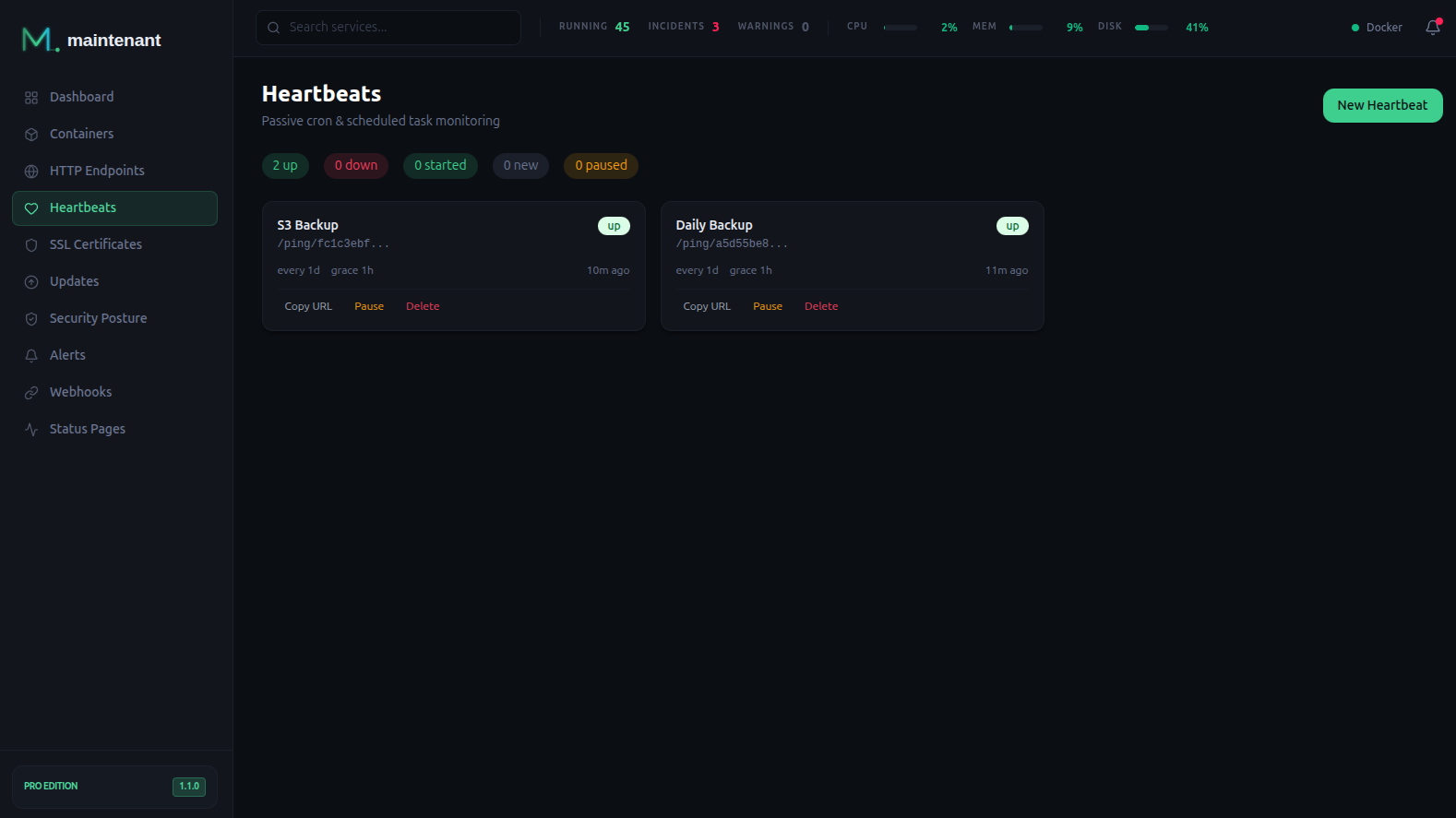
4. Monitoring des cron jobs
Les tâches planifiées sont les services les plus oubliés. Votre backup nocturne tourne-t-elle vraiment ? Votre job de nettoyage s’est-il terminé correctement ?
Le pattern heartbeat : votre cron envoie un ping à une URL après chaque exécution. Si le ping ne vient pas dans le délai attendu, vous êtes alerté.
# Ajoutez une ligne à votre crontab
0 3 * * * /usr/local/bin/backup.sh && curl -fsS -o /dev/null https://now.example.com/ping/{uuid}/$?
5. Monitoring des ressources système
Les métriques critiques
- Espace disque — un disque plein peut crasher votre base de données
- Utilisation mémoire — par conteneur et par hôte
- CPU — pour détecter les pics anormaux
- I/O réseau — pour identifier les congestions
Maintenant collecte ces métriques via l’API Docker stats et les affiche en temps réel avec des graphiques historiques.
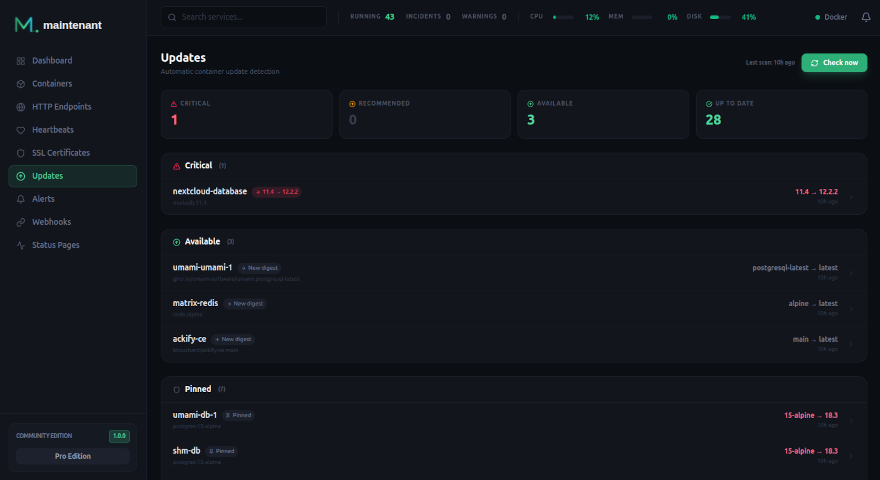
6. Détection des mises à jour
Savoir qu’une mise à jour de sécurité est disponible pour votre image PostgreSQL ou Redis est critique. Maintenant scanne les registres OCI et compare les digests pour vous alerter des mises à jour disponibles.
Mettre tout ça en place en 30 secondes
Avec Maintenant, ces 6 dimensions de monitoring sont couvertes par un seul conteneur :
services:
maintenant:
image: ghcr.io/kolapsis/maintenant:latest
ports:
- "8080:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /proc:/host/proc:ro
- maintenant-data:/data
environment:
MAINTENANT_ADDR: "0.0.0.0:8080"
MAINTENANT_DB: "/data/maintenant.db"
restart: unless-stopped
volumes:
maintenant-data:
Vos conteneurs sont découverts automatiquement. Ajoutez des labels pour les endpoints et les alertes. C’est tout.