Le Problème de la Complexité
Prometheus + Grafana est la stack de monitoring de référence. Elle fait tourner certaines des plus grandes infrastructures du monde. Mais pour un stack Docker Compose typique de 10-50 conteneurs sur un VPS, c’est massivemment surdimensionné.
Pour monitorer vos conteneurs avec la stack Grafana, vous avez besoin au minimum de :
- Prometheus — collecte et stockage des métriques
- cAdvisor — expose les métriques conteneurs à Prometheus
- Grafana — visualisation et dashboards
- node_exporter — métriques système de l’hôte (recommandé)
- Alertmanager — routage des alertes (si vous voulez des notifications)
Soit 3 à 5 conteneurs supplémentaires juste pour monitorer vos conteneurs existants. Chacun avec sa propre configuration, ses propres mises à jour, ses propres modes de défaillance. L’ironie : votre stack de monitoring peut tomber indépendamment de vos applications.
Et puis il y a PromQL. Écrire une règle d’alerte pour “mon conteneur Redis utilise plus de 80% de sa mémoire allouée” nécessite :
container_memory_usage_bytes{name="redis"} /
container_spec_memory_limit_bytes{name="redis"} > 0.8
Avec Maintenant, vous ajoutez un label Docker et les seuils par défaut font le reste.
Qui Ne Devrait PAS Migrer
Maintenant ne remplace pas Prometheus + Grafana si vous avez besoin de :
- Requêtes ad-hoc — PromQL permet d’explorer et corréler n’importe quelle métrique. Maintenant a des vues pré-construites sans langage de requête.
- Dashboards personnalisés — Le builder de dashboards Grafana est inégalé. Les vues de Maintenant sont opinionnées et fixes.
- Rétention longue durée — Prometheus peut stocker des années de données haute résolution. Maintenant conserve 7 jours (Community) ou 1 an (Pro).
- Fédération multi-cluster — La fédération Prometheus agrège les métriques entre clusters. Maintenant est par hôte ou par cluster.
- Métriques applicatives — Si votre app Go/Java/Python expose des métriques Prometheus custom, Maintenant ne les scrape pas.
Si vous avez une équipe SRE dédiée et des centaines de microservices, restez sur Prometheus + Grafana.
Qui Devrait Migrer
- Self-hosters qui passent plus de temps à configurer Prometheus qu’à faire tourner leurs services
- Petites équipes qui ont besoin de “est-ce que tout tourne ?” pas “quel est le p95 de la durée de requête dans mon service mesh ?”
- Développeurs qui veulent du monitoring sans apprendre PromQL, créer des dashboards Grafana, ou maintenir une stack de 5 conteneurs
- Passionnés de homelab fatigués de voir cAdvisor consommer 200+ Mo de RAM juste pour exposer des métriques conteneurs
Maintenant vs Prometheus + Grafana — Comparatif
| Fonctionnalité | Prometheus + Grafana | Maintenant |
|---|---|---|
| Monitoring conteneurs | ✓ (via cAdvisor) | ✓ (intégré) |
| Auto-découverte | ✗ (targets manuels) | ✓ |
| Checks HTTP/TCP | ✗ (nécessite Blackbox Exporter) | ✓ |
| Monitoring certificats SSL | ✗ (exporter séparé) | ✓ |
| Heartbeat / monitoring cron | ✗ | ✓ (10 gratuits, illimités Pro) |
| Métriques CPU / RAM / disque | ✓ | ✓ |
| Détection de mises à jour (digest OCI) | ✗ | ✓ |
| Page de statut publique | ✗ | ✓ (Pro : incidents, maintenance) |
| Analyse sécurité réseau | ✗ | ✓ (Pro : CVE + score de risque) |
| Alertes | ✓ (Alertmanager) | Webhook + Discord (gratuit), Slack/Teams/Email (Pro) |
| Requêtes custom (PromQL) | ✓ | ✗ |
| Dashboards personnalisés | ✓ | ✗ |
| Métriques applicatives | ✓ | ✗ |
| Fédération multi-cluster | ✓ | ✗ |
| Self-hosted | ✓ | ✓ |
| Conteneurs nécessaires | 3-5 | 1 |
| Fichiers de config | prometheus.yml + par exporter | 0 |
| Temps d’installation | 1-2 heures | 30 secondes |
| RAM au repos | 500+ Mo (combiné) | ~17 Mo |
| Prix | Gratuit | Gratuit (Community) / 9 €/mois (Pro) |
Les Chiffres
| Prometheus + Grafana | Maintenant | |
|---|---|---|
| Conteneurs à déployer | 3-5 (Prometheus, Grafana, cAdvisor, node_exporter, Alertmanager) | 1 |
| Fichiers de config à écrire | 3+ (prometheus.yml, alertmanager.yml, datasources Grafana) | 0 |
| Temps avant premier dashboard | 1-2 heures | 30 secondes |
| Empreinte RAM au repos | ~500 Mo+ combiné | ~17 Mo |
| Courbe d’apprentissage | PromQL + builder Grafana | Aucune |
Ce Que Vous Obtenez avec Maintenant
Un conteneur. Zéro fichier de config. Tout est monitoré :
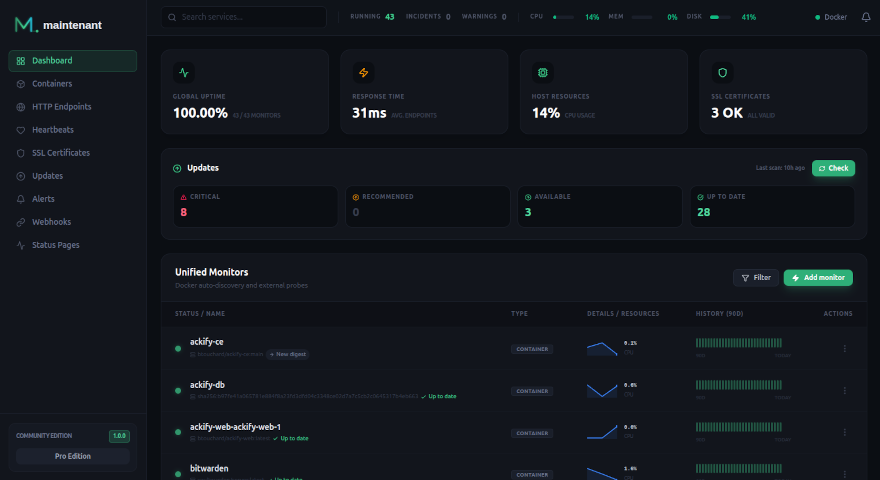
- Auto-découverte des conteneurs — Docker et Kubernetes, pas de targets à déclarer
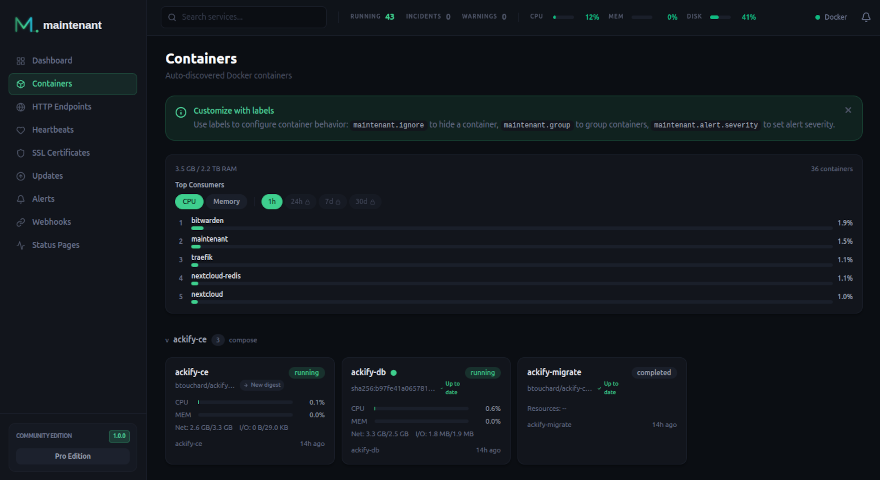
- Monitoring HTTP/TCP — configuré par labels Docker, pas de Blackbox Exporter
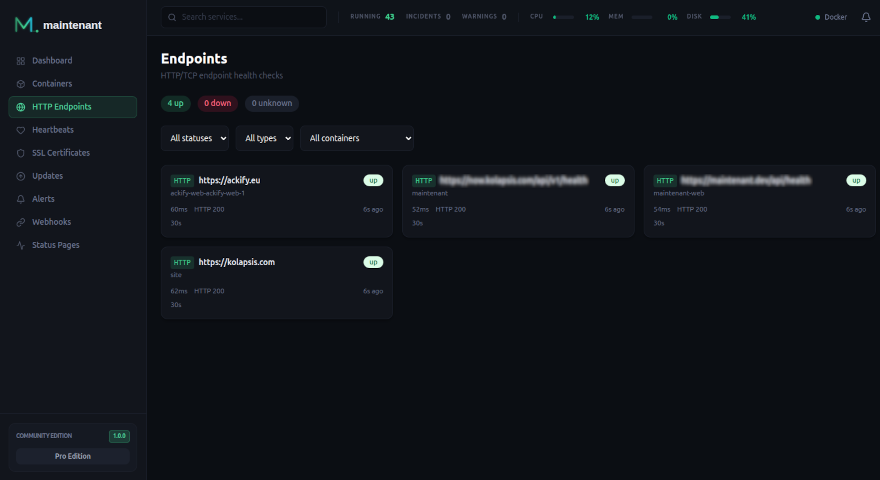
- Suivi des certificats SSL/TLS — détection automatique, pas d’exporter séparé
- Monitoring heartbeat / cron — intégré, pas d’outil externe (10 gratuits, illimités avec Pro)
- Ressources système — CPU, RAM, réseau, disque par conteneur et par hôte
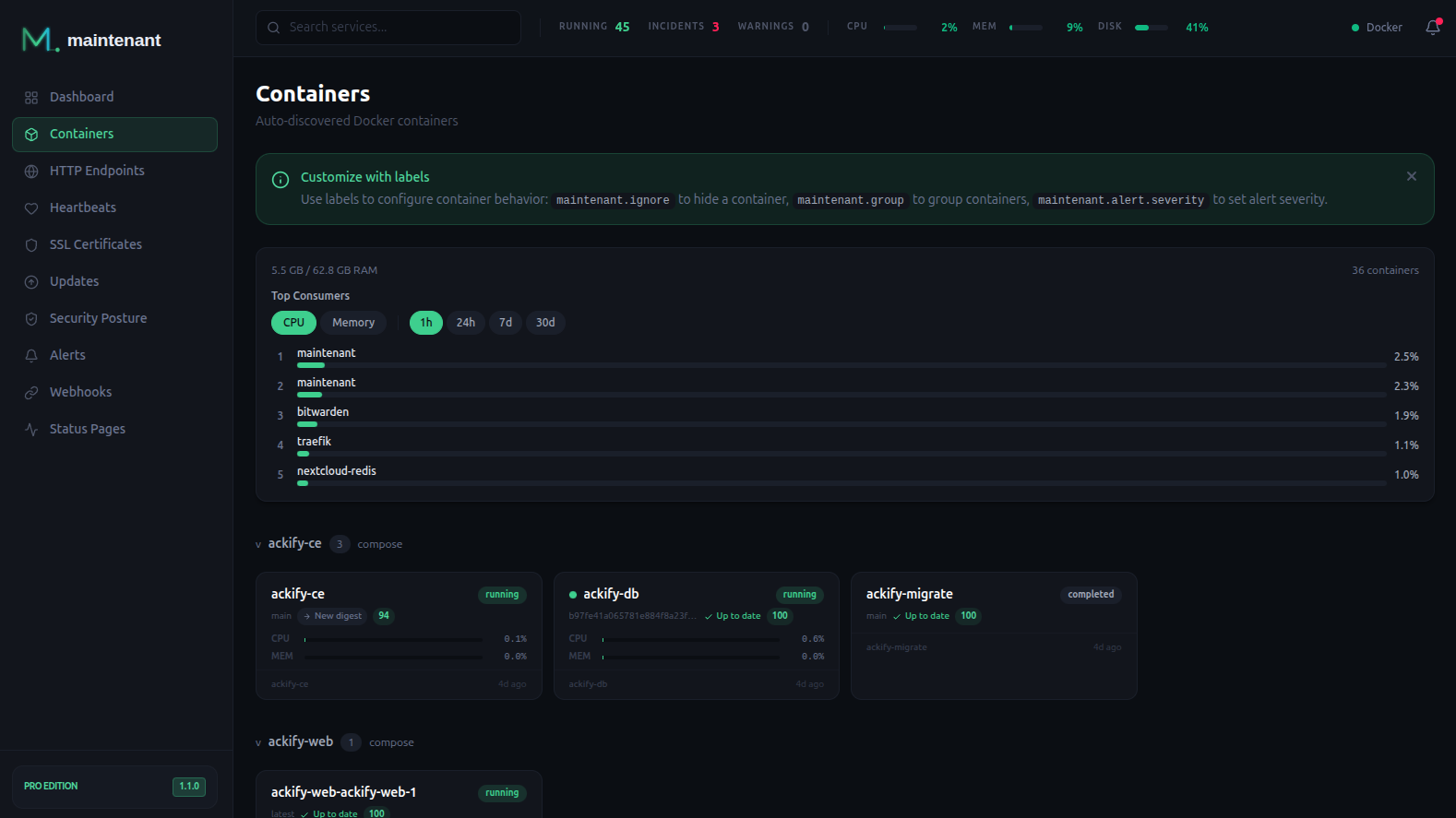
- Update intelligence — scan digest OCI sur tous vos conteneurs
- Alertes unifiées — webhook, Discord (Community), Slack, Teams, Email (Pro)
- Page de statut publique — temps réel, mises à jour SSE (Pro : gestion d’incidents, fenêtres de maintenance)
Migrer depuis Prometheus + Grafana
Pas de migration de données nécessaire. Déployez Maintenant à côté de votre stack existante, vérifiez qu’il couvre vos besoins, puis supprimez Prometheus, Grafana, cAdvisor et le reste :
# docker-compose.yml — remplacez 5 conteneurs par 1
services:
maintenant:
image: ghcr.io/kolapsis/maintenant:latest
ports:
- "8080:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /proc:/host/proc:ro
- maintenant-data:/data
environment:
MAINTENANT_ADDR: "0.0.0.0:8080"
MAINTENANT_DB: "/data/maintenant.db"
restart: unless-stopped
volumes:
maintenant-data:
docker compose up -d
Ouvrez http://votre-serveur:8080 — vos conteneurs sont déjà là. Pas de prometheus.yml. Pas de datasources Grafana. Pas de PromQL.
FAQ
Puis-je faire tourner Maintenant à côté de Prometheus pendant une transition ? Oui. Maintenant est en lecture seule et n’interfère avec aucun autre outil de monitoring.
J’ai des métriques Prometheus custom dans mes apps. Maintenant peut-il les scraper ? Non. Maintenant monitore la couche infrastructure (conteneurs, endpoints, certificats, ressources), pas les métriques applicatives. Si vous avez besoin des deux, gardez Prometheus pour les métriques app et utilisez Maintenant pour tout le reste.
Et Grafana Cloud ou Prometheus-as-a-Service ? Si vous payez déjà un service Prometheus managé, Maintenant offre une alternative radicalement plus simple (et moins chère) pour le monitoring d’infrastructure. Mais il ne remplace pas l’observabilité applicative.
Maintenant supporte-t-il Kubernetes ? Oui. Il détecte automatiquement le runtime et utilise un RBAC read-only pour découvrir les workloads.